
Sometimes, we might want to run a single program with many input files. For example, if we want to resize or crop a large number of photos to the same dimensions. The long way would be to open the first file in a photo editing program and manually resize it, then open the next one, do it again and so on. But, of course we are faster if we automate the task and, most important, use multiple processor cores for parallel processing. Certainly, there are specialized software tools that will do a batch resizing of images for you (most likely not in parallel, though). However, here I will demonstrate a structured and flexible way of applying a program to multiple files in parallel on the command line in a Linux environment using xargs.
So, let’s come up with a minimal example just to illustrate the problem and the solution.
Create a test case
First we need to generate some test data. For that, I want to create a directory structure with two levels. First we create directories for the years 2019 and 2020. For each year, we want directories for the 12 months. The final directory structure should look like the following (short version).
.
├── 2019
│ ├── 01
| ...
│ └── 12
└── 2020
├── 01
...
└── 12
This script will quickly create the structure for you.
#!/bin/bash
years=(2019 2020)
months=("01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12")
for year in ${years[@]}
do
for month in ${months[@]}
do
mkdir -p ./${year}/${month}
done
doneCode language: Bash (bash)Now, we want to create a test file in each subdirectory that contains some text. We can do this with the echo command in the following script.
#!/bin/bash
years=(2019 2020)
months=("01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12")
for year in ${years[@]}
do
for month in ${months[@]}
do
echo "This is the teexxt file for month "${month}" of the year "${year}"!" > ./${year}/${month}/testfile_${year}_${month}.txt
done
doneCode language: Bash (bash)After running this script you will find the newly created files in the directories.
. ├── 2019 │ ├── 01 │ │ └── testfile_2019_01.txt │ ├── 02 │ │ └── testfile_2019_02.txt ...
Let’s have a look at the first file. It only contains one line.
This is the teexxt file for month 01 of the year 2019!
Process the files in batch mode
As you can see above, I made a typo which will appear in all files. Of course, we can fix this by spending some time on editing each file manually. But the purpose of this tutorial is to show you a way of doing it automated and, eventually, with some degree of parallelism.
Concerning fixing the typo, we can use the tool sed to replace the misspelled word with the correct one. For the first file, we could run it like this…
sed -i 's/teexxt/text/g' testfile_2019_01.txtCode language: Bash (bash)This sed command replaces the word teexxt with text. To apply the command to all files, we can use the same method that we used to create them. The result is the following script.
#!/bin/bash
years=(2019 2020)
months=("01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12")
for year in ${years[@]}
do
for month in ${months[@]}
do
sed -i 's/teexxt/text/g' ./${year}/${month}/testfile_${year}_${month}.txt
done
doneCode language: Bash (bash)Note, how we used the iterator variables ${year} and ${month} to construct the path and filename.
Use xargs to parallelize
So, we now have a batch script that corrects the typo in all files. For our test data, this finishes in less than a blink of the eye. However, in reality we could have thousands of files and each execution could take several seconds or minutes, which would result in a total processing time of hours or even days. Since most computers in our days have two, four or even 16 processor cores, we can save a substantial amount of computation time when we make them all sweat.
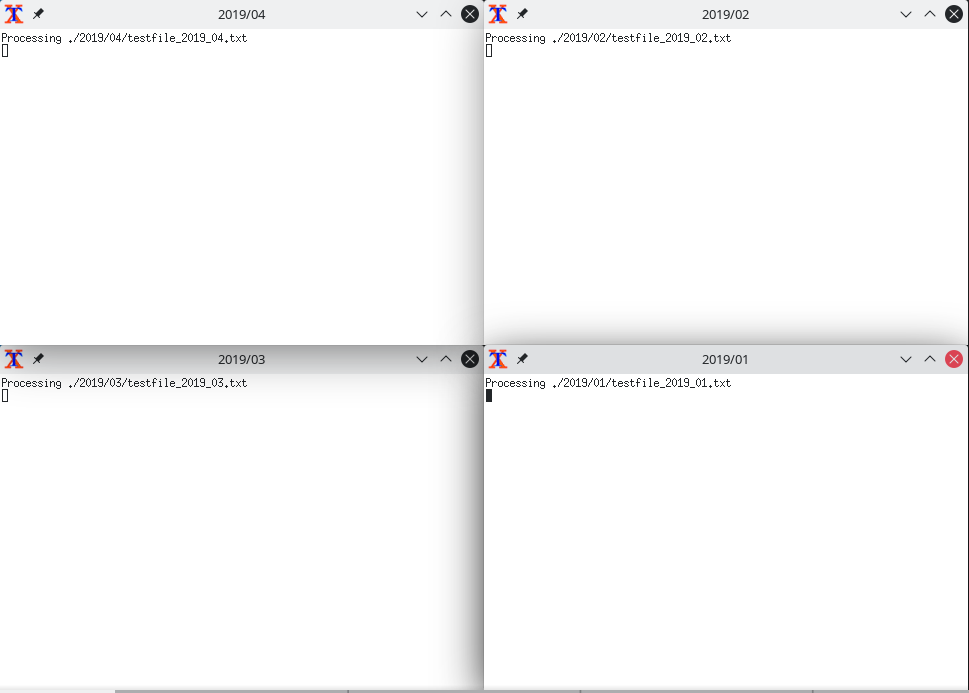
Thanks to xargs we can achieve this very comfortably. We use it here together with xterm to run each instance of sed in a separate terminal. This gives us a better structured way of following the output of each running process.
#!/bin/bash
years=(2019 2020)
months=("01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12")
for year in ${years[@]}
do
printf '%s\n' "${months[@]}" | xargs -I "%" -P 4 xterm -T ${year}/% -e /bin/bash -c "echo 'Processing './${year}/%/testfile_${year}_%.txt && sed -i 's/teexxt/text/g' ./${year}/%/testfile_${year}_%.txt"
doneCode language: Bash (bash)At first, this script and the command withing it might look overwhelming. Let’s break it down piece by piece. First, you will notice that we only use one loop, the one for the years. This is due to the way xargs works. xargs takes input from the command line standard input (stdin) and let’s you use it to construct commands. This is why we first call printf '%s\n' "${months[@]}" to print all items from months separated by newline characters to stdin. We use a pipe | to forward this list to xargs. We run xargs on this list with only two options. The -I "%" sets the % symbol as a placeholder for the months in the list. The number of instances xargs runs depends on the -P flag. Here, I use 4, since my laptop has four cores.
In the next section of the command, we start xterm with the year/month as the window title (-T ${year}/%). Inside xterm, we will run a bash shell with the command (/bin/bash -c) that is enclosed in the double quotes. This includes a statement to print a message to stdout, followed by the actual sed construct that will correct the typo in the text file.
In a nutshell, the script above will process one year after another, but, for each year xargs will run four instances of the sed command, each one for a different month. Whenever a full set of four instances has finished, xargs will start a new set. By encapsulating each instance in a xterm terminal window, we can monitor the progress constantly.
Sources and further reading
- https://www.man7.org/linux/man-pages/man1/xargs.1.html
- https://man7.org/linux/man-pages/man1/sed.1.html
- https://stackoverflow.com/questions/28357997/running-programs-in-parallel-using-xargs
- https://linuxize.com/post/how-to-use-sed-to-find-and-replace-string-in-files/
- https://linuxhandbook.com/bash-printf/